Companies typically pay a lot of money to serve online aggregated analytics features using Pinot, Druid, etc - but there's a poor man's version that actually works pretty well:
A DuckDB-backed analytics service.
I've done this and it works really well for 10s of millions of rows and is easy to manage. The main caveat is that this works if you can tolerate lower data freshness and your data needs to be able to fit in a single machine (though you can vertically scale quite a lot pretty cheaply).
The service pulls all the data on server start and polls from the data source on your desired frequency (poor man's CDC), stores it in the local duckdb, and you throw a FastAPI layer to translate requests to queries.
Added bonus: If your data is on Postgres, you can use the DuckDB Postgres Scanner extension to do this really easily.
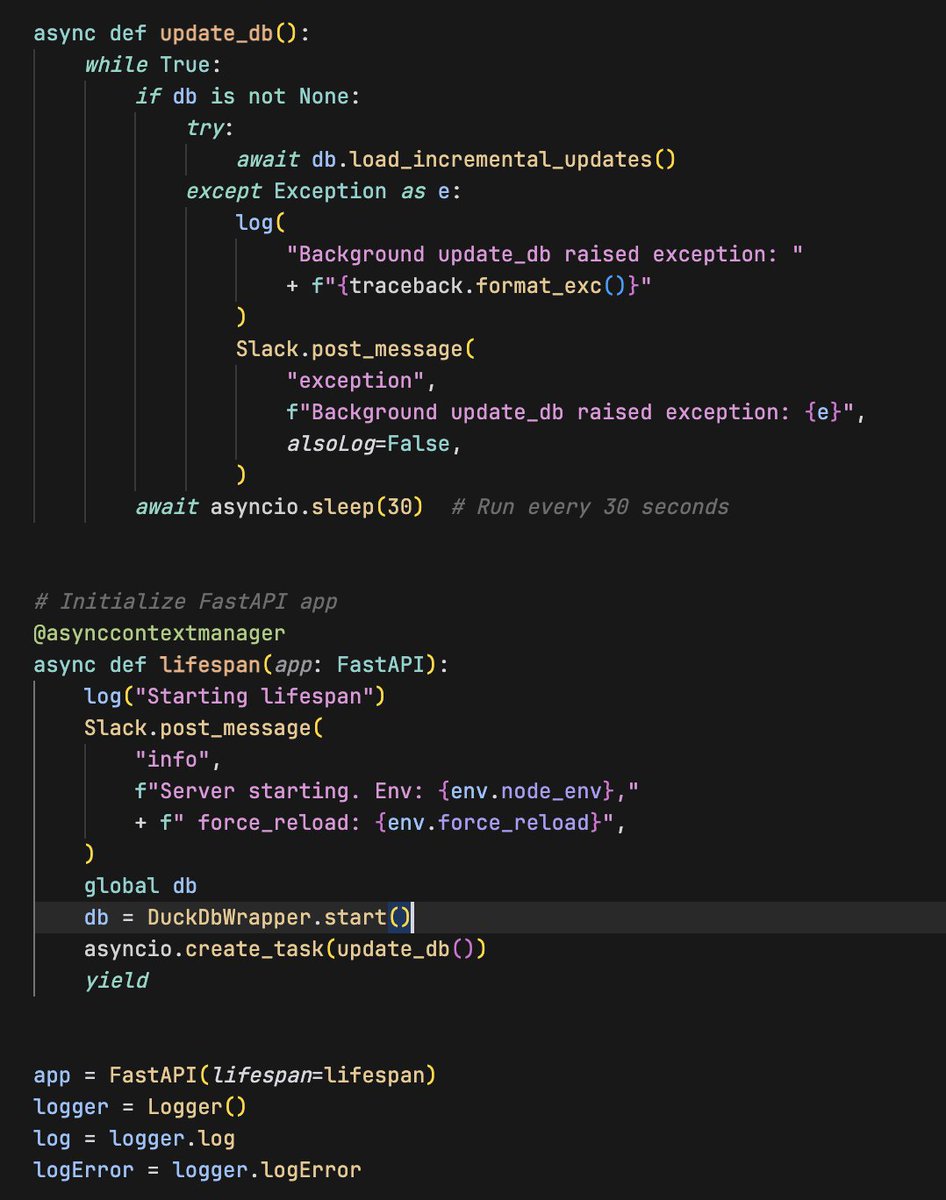
In theory you could also do this fully serverless using S3 for storage (a la BoilingData) but the performance / cost tradeoff will be different since DuckDB will cache a lot of things locally.
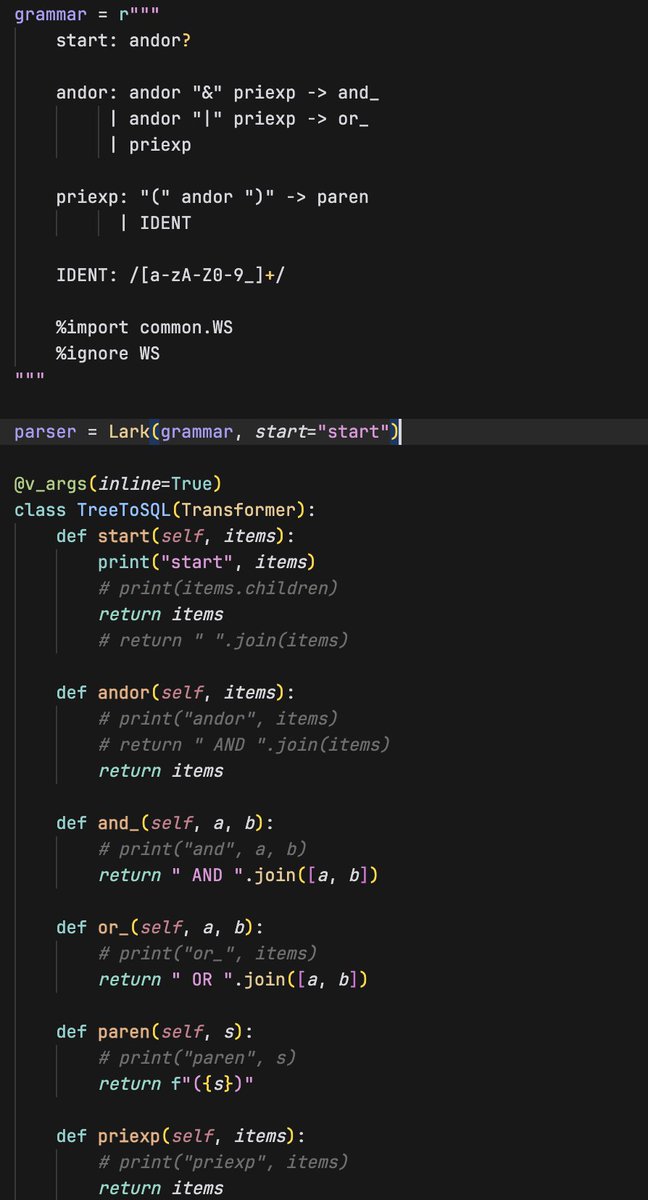
This approach is particularly powerful if you need to support arbitrary query capabilities from your users, where you can use something like Lark + SQL Alchemy to dynamically translate your particular query language / API to SQL (be careful here 😅).
For my particular use case, this solution would cost ~$X0/month rather than the ~$X00-$X000 that running it on top of a data warehouse would cost. You may still end up needing to use Pinot or Druid at some point but this quick and dirty way will take you pretty far 🫡